Text Generator With Transformer Decoder
0. 前言
这篇 Blog 主要聚焦于利用 Transformer 的 Decoder 实现一个简单的 text generator. 虽然代码相对简单, 但是核心思想类似, 做个记录, 方便后续学习理解. 主要参考 : https://wingedsheep.com/building-a-language-model/
阅读前, 需要你 : 了解 Transformer结构, Attention机制, Mask Attention机制, 了解 Pytorch 以及 NLP 相关的基础知识, 比如 token, embedding, 序列之类的.
1. 准备
首先需要搞明白真正在编程实现一个 text generator 的时候, 代码核心是什么? 我们来列出任务的基本组成:
- 数据构造
- 输入 : 一个序列
- 输出 : 一个单词 或者 一个序列
- 模型实现
- positional encoding
- token embedding
- decoder layer
- mask attention (multi-head)
- mlp, layer normalization, active function…等常规组件
- 文本生成
- 让输出持续下去!
其中
[1] 数据构造 步骤是需要针对我们的任务单独构造实现 (核心)
[2] mask attention 是 decoder 结构的核心, 这个没的说
[3] 目标 : 文本生成 , 核心没的说.
其他的, positional encoding, token embedding 以及 mlp 等组件都是常规操作, 不足为虑. 因此我们将从上述3个方面来入手.
2. 数据构造
2.1 让计算机处理文字
文本生成任务是说, 我们想让模型根据一个简单提示词, 然后接着提示词不断的写下去. 比如, 给模型输入: “我爱您,”, 那么模型也许能够输出: “母亲, 感谢您的养育之恩.” 最后我们将输入和输出连起来得到完整的语句: “我爱您, 母亲, 感谢您的养育之恩.”
不过计算机没法处理汉字, 英文也不认识. 所以我们首先需要把英文啊, 中文转成数字.
怎么转呢? 其实非常简单, 假设我们汉字有10w个, 我们就把每个汉字和一个数字一一对应即可. 比如 :

注意这里, 标点符号也是要进行转换. 好的, 现在我们可以把汉字或者单词输入到模型中了.
不过汉字太多了, 为方便叙述, 后续我们使用英文来举例子. 本文我们就用到的 a-z 26个字母 + 0-9 10个数字 + '\ ' + ',' + '.' + '<pad>'共40个字符, 我们称之为 ‘vocabulary’. 其中, '<pad>' 用于对句子进行填充, 使得训练的时候, 输入的句子一样长. 以下代码实现将这些字符映射到数字.
详细信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class Tokenizer:
r'''
0-9 (10 个 token) , a-z (26 个 token) , ' ' , ',' '.' , '<pad>' 共40个token
'''
def __init__(self):
self.dictionary = {}
self.reverse_dictionary = {}
# Add the padding token
self.__add_to_dict('<pad>')
# Add characters and numbers to the dictionary
for i in range(10):
self.__add_to_dict(str(i))
for i in range(26):
self.__add_to_dict(chr(ord('a') + i))
# Add space and punctuation to the dictionary
self.__add_to_dict(',')
self.__add_to_dict('.')
self.__add_to_dict(' ')
def __add_to_dict(self, character):
if character not in self.dictionary:
self.dictionary[character] = len(self.dictionary)
self.reverse_dictionary[self.dictionary[character]] = character
def tokenize(self, text):
return [self.dictionary[c] for c in text]
def character_to_token(self, character):
return self.dictionary[character]
def token_to_character(self, token):
return self.reverse_dictionary[token]
def size(self):
return len(self.dictionary)
2.2 输入输出构造
我们的训练集是一句话 : “cats rule the world. dogs are the best. elephants have long trunks. monkeys like bananas. pandas eat bamboo. tigers are dangerous. zebras have stripes. lions are the kings of the savannah. giraffes have long necks. hippos are big and scary. rhinos have horns. penguins live in the arctic. polar bears are white”
以下列出了几组输入和输出样例 (假设每句话最大token数目限制为3) :
[1]
'cat' -> 'ats'[2]
'ats' -> 'ts '[3]
'ts ' -> 's r'
使用如下代码将字符转换为数字.
详细信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# Create the training data
training_data = '. '.join([
'cats rule the world',
'dogs are the best',
'elephants have long trunks',
'monkeys like bananas',
'pandas eat bamboo',
'tigers are dangerous',
'zebras have stripes',
'lions are the kings of the savannah',
'giraffes have long necks',
'hippos are big and scary',
'rhinos have horns',
'penguins live in the arctic',
'polar bears are white'
])
tokenized_and_padded_training_data = tokenize_and_pad_training_data(max_sequence_length, tokenizer, training_data)
def tokenize_and_pad_training_data(max_sequence_length, tokenizer, training_data):
# Tokenize the training data
tokenized_training_data = tokenizer.tokenize(training_data)
for _ in range(max_sequence_length):
# Prepend padding tokens
tokenized_training_data.insert(0, tokenizer.character_to_token('<pad>'))
return tokenized_training_data
字符转数字处理后的结果 tokenized_and_padded_training_data

ok , 经过上边的映射, a就是 11 , b 就是 12, 假设我们想输入 abc, 希望模型预测的输出是 d . 那输入就是 11 12 13, 输出就是 14, 即 11 12 13 -> 14.
本篇 blog 使用 11 12 13 -> 12 13 14 的输出格式, 本质是一样的. 这样保证了输入输出的序列长度是一样的. 此外代码中实现的时候, 我们假设序列的长度为 $20$ . 一句话不足 $20$ 个 token, 用<pad>字符填充(就是用0填充). 举个例子:
用 1 2 3 -> 2 3 4 , 经过填充后, 最后实际给模型的输入输出为 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 -> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 2 3 4
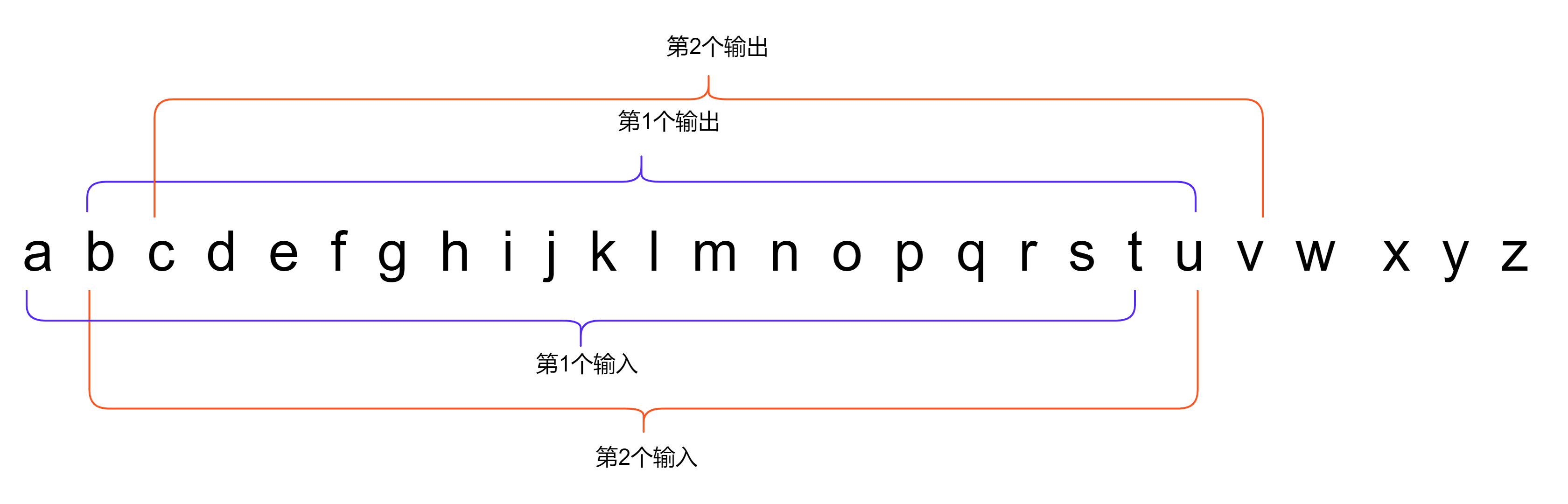
你可能注意到, 我们在整个句子前边添加了 20 个<pad>字符. 这是为了下一步对输入输出构造, 对于第一组输入和输出.
输入 ‘空白符’ , 输出’c’:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
-> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13
其他组的输入和输出, 其构造过程就是一个滑动窗口:
构造过程代码:
1
2
3
4
5
6
7
8
# ...
sequences = create_training_sequences(max_sequence_length, tokenized_and_padded_training_data)
def create_training_sequences(max_sequence_length, tokenized_training_data):
sequences = []
for i in range(0, len(tokenized_training_data) - max_sequence_length - 1):
sequences.append(tokenized_training_data[i: i + max_sequence_length + 1])
return sequences
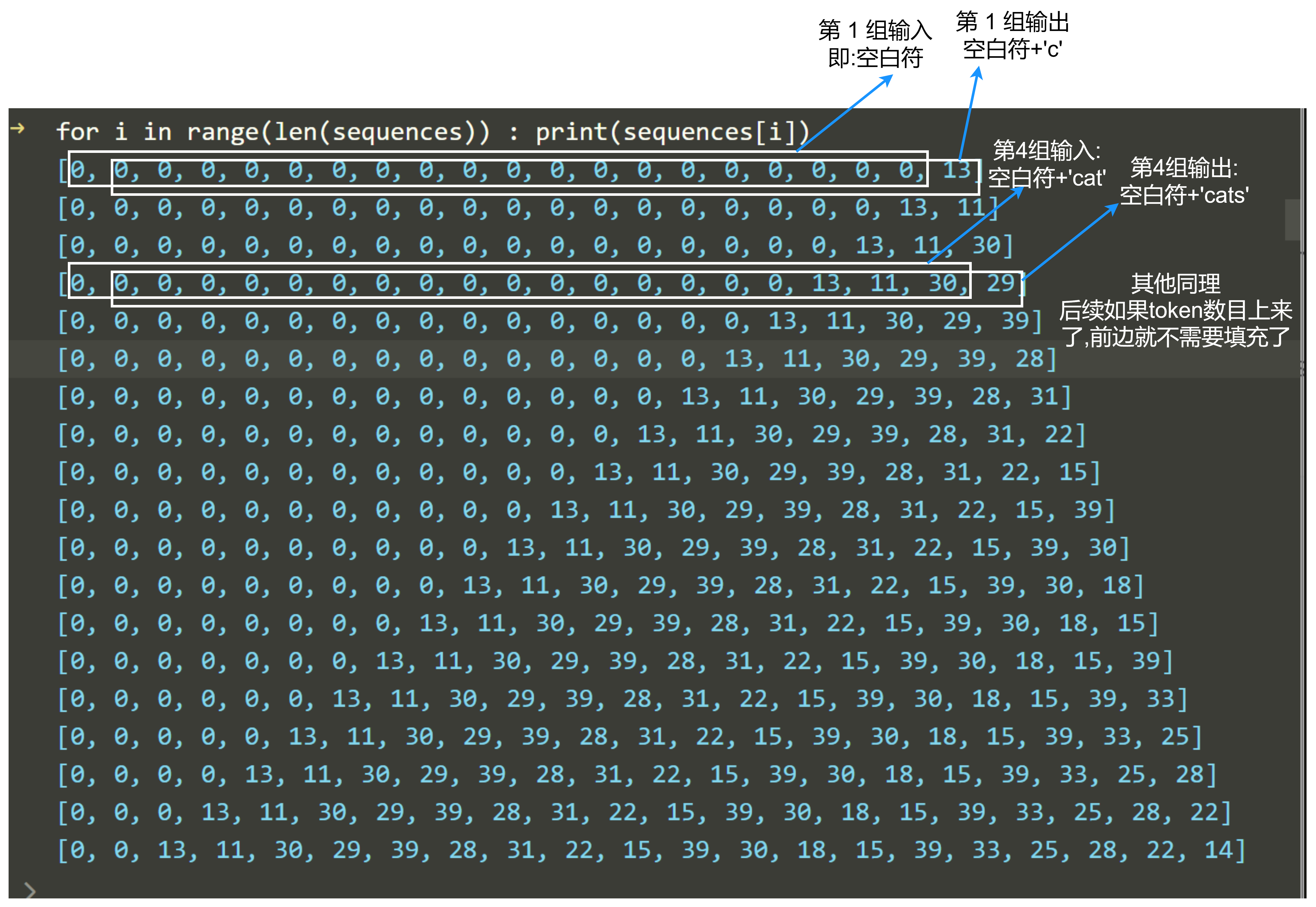
最后每一组的输入和输出构造结果sequences如下:
这里为了表示方便, 我们把输入和输出放到一个list里边, 因为输入和输出就差一个字符
3. Mask Attention
假设输入是 ‘cat’, 经过填充就是 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 13, 11, 30
假设这个序列的Attention矩阵如下:

Attention不说了, 这里 Mask 主要有2个缘由:
[1] 由于我们的输入数据中含有填充字符(这个过程叫padding), 而这些填充字符是没有实际意义的。因此,在进行注意力计算时,我们希望有效的token不会与这些填充字符attention, 因此需要对attention权重矩阵应用padding mask
[2] 此外,由于我们的任务是文本生成,字符是按顺序一个接一个地生成的,从左到右逐步产生。因此,我们希望当前的token只能注意到其左侧的token, 不允许其注意到未来的token.
3.1 Padding Mask
Padding Mask 中, 1 表示当前输入允许注意的位置. 举个例子:

当然如果没有 padding 字符, 那自然 padding mask 就全是 1 了.
注意这里, Padding Mask 不负责 “当前 token 不允许与右侧 token 做attention”, 这部分由 Causal Mask 负责.
这样经过 Padding Mask 后, Attention 矩阵应该如下:
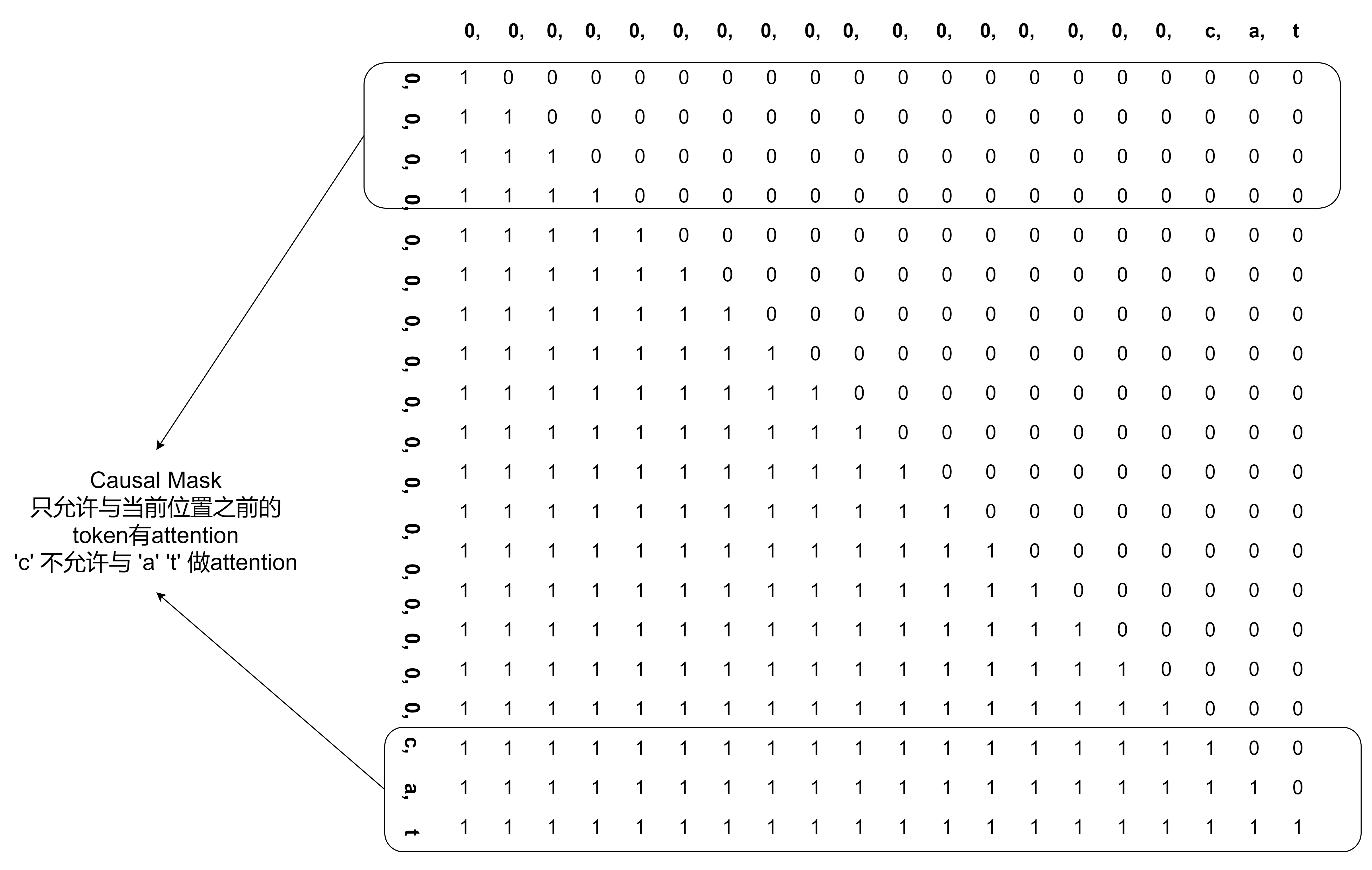
3.2 Causal Mask
Causal Mask 就常规了, 一个 shape with $序列长度 \times 序列长度$ 的下三角矩阵.
3.3 武魂融合, 启动!
那实际中我们是 “两手都要抓,两手都要硬”, 即需要 “Padding Mask” 也需要 “Causal Mask”.
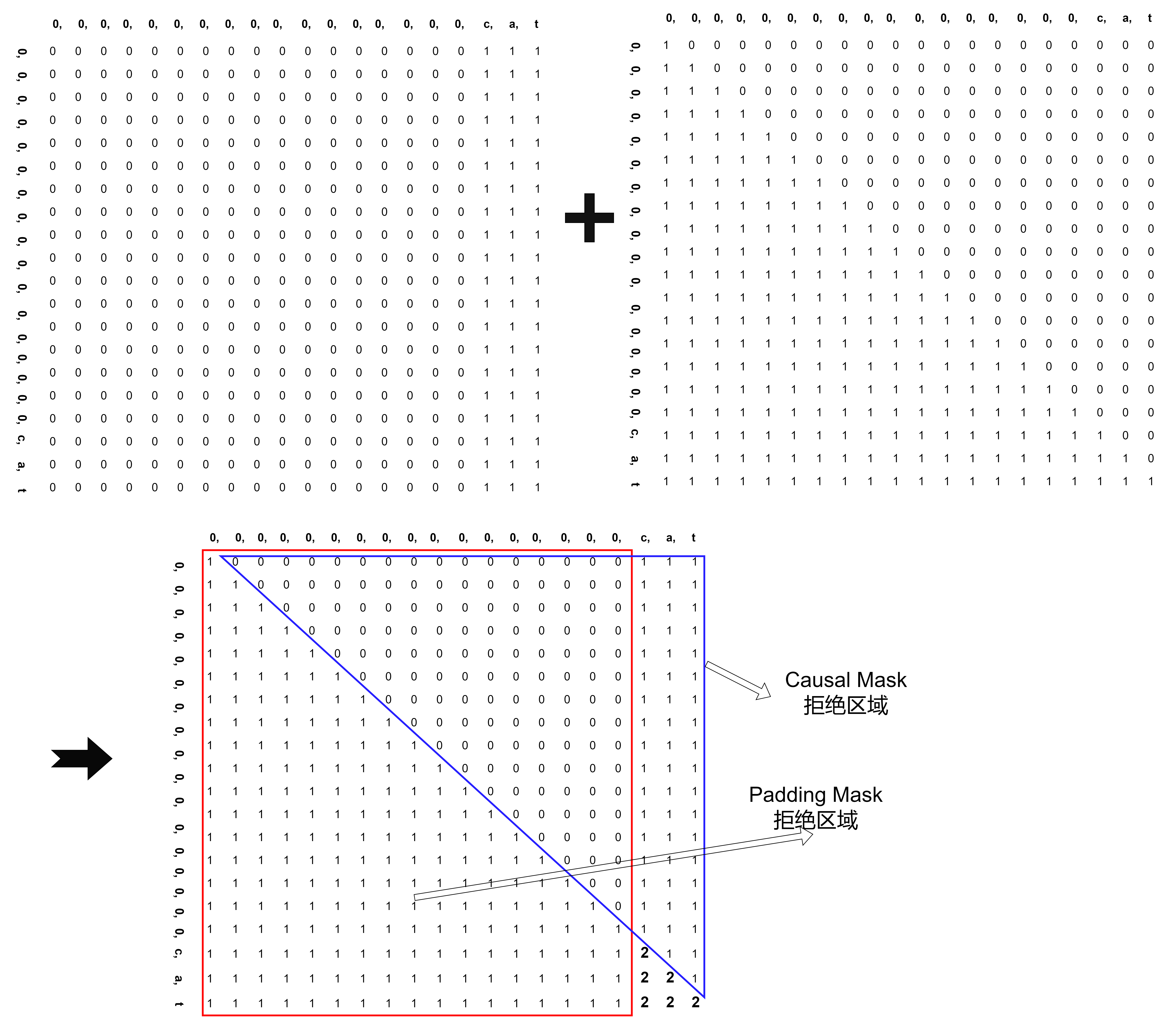
最后, 我们可以看到, 只有 “2” 的位置 Attention score 是允许的, 其余位置都不可以.
4. 文本生成
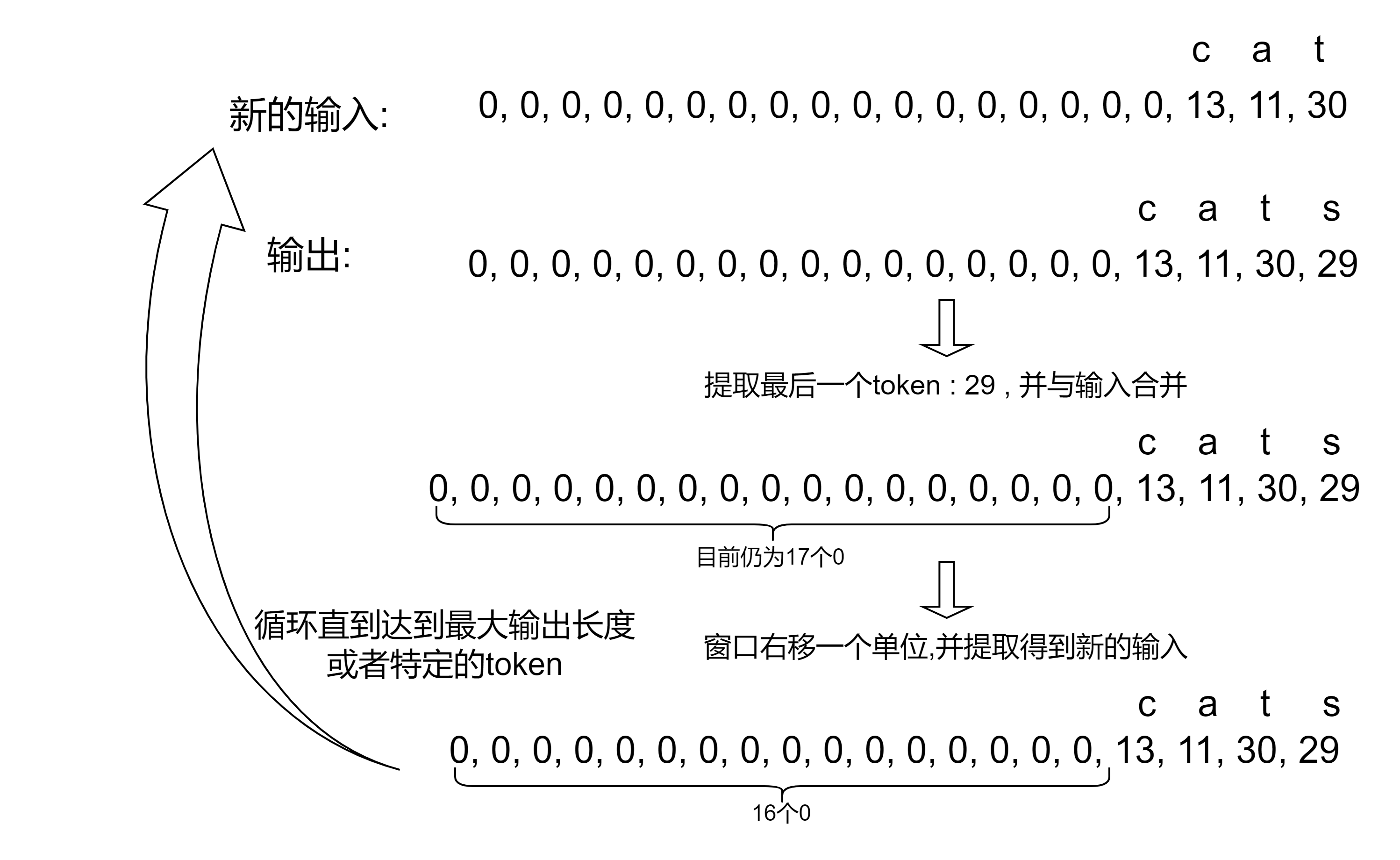
这里最后我们模型输出的是下一个 token 在 vocabulary 上的概率, 因此具体下个 token 具体是什么, 需要采样, 采样思路有很多, 可以参考: how-to-generate. 不过这篇 Blog 就简单的输出概率最大的那个token.
5. 完整代码
完整代码见: Text-Generator-With-Decoder