Lang Chain Series
0. 前言
本篇 Blog 不是教程, 官方教程1、2 有时候比较抽象, 这里只是在学习 LangChain 过程中做个记录, 并加入自己的理解和注释. 当然这里也不进行过多的介绍, 直接进入对组件的学习.
1. Prompts
Prompts 通常用来”调教”LLM, 比如用来指定 LLM 的输出格式, 也可以用来给 LMM 一些例子让他参考等等.LangChain 目前提供了 4 种 Prompts template , 方便用户构造 Prompt.
1.1 PromptTemplate
PromptTemplate 是最简单, 最基本的一种 Template. API Reference:PromptTemplate
官方给了 2 种方法来用 PromptTemplate.
- 方法一(推荐)
1
2
3
4
5
from langchain_core.prompts import PromptTemplate
# Instantiation using from_template (recommended)
prompt = PromptTemplate.from_template("Say {foo}")
prompt.format(foo="bar")
结果 : Say bar
- 方法二
1
2
3
4
5
6
from langchain_core.prompts import PromptTemplate
# Instantiation using initializer
prompt = PromptTemplate(input_variables=["foo"], template="Say {foo}")
prompt.format(foo="bar")
结果 : Say bar
1.2 ChatPromptTemplate
ChatPromptTemplate 通常有 3 种规则: “system”, “ai” and “human”. API Reference:ChatPromptTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
输出:
1
2
3
4
5
[SystemMessage(content='You are a helpful AI bot. Your name is Bob.'),
HumanMessage(content='Hello, how are you doing?'),
AIMessage(content="I'm doing well, thanks!"),
HumanMessage(content='What is your name?')]
可以看到, 实际是产生了 SystemMessage, HumanMessage and AIMessage 共 3 种 Message. 与之对应的, 在构造这些 Message 时, 可以使用相应的 Template : AIMessagePromptTemplate, SystemMessagePromptTemplate and HumanMessagePromptTemplate
例子:
1
2
3
4
5
6
7
8
9
10
11
12
from langchain_core.prompts import HumanMessagePromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个{llm_type}"), # 使用 template构造 系统的 message
('ai', "很高兴帮助您."), # 直接使用 role 构造 AI的 message
HumanMessagePromptTemplate.from_template("{text}"),
]
)
messages = chat_template.format_messages(llm_type="AI助手", text = "1 + 1 = ?")
print(messages)
输出:
1
2
3
[SystemMessage(content='你是一个AI助手'),
AIMessage(content='很高兴帮助您.'),
HumanMessage(content='1 + 1 = ?')]
1.3 Example selectors
假设有一些例子, 我们希望 LLM 能够根据输入挑一些合适的例子出来, 方便我们后续的操作, 比如将他们放到一个 prompt 中. API Reference
Select by length
简单来说, 这个 selector 是根据用户输入的语句长短选择合适的 example, 你输入的越短,他给的例子越多, 你输出的越长,他给的例子越少.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
# 这个参数有些 selector 不需要, 有些是必须的, 请参考函数具体API
example_prompt=example_prompt,
# The maximum length that the formatted examples should be.
# Length is measured by the get_text_length function below.
max_length=25,
# The function used to get the length of a string, which is used
# to determine which examples to include. It is commented out because
# it is provided as a default value if none is specified.
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
输入:
1
2
# An example with small input, so it selects all examples.
print(dynamic_prompt.format(adjective="big"))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Give the antonym of every input
Input: happy
Output: sad
Input: tall
Output: short
Input: energetic
Output: lethargic
Input: sunny
Output: gloomy
Input: windy
Output: calm
Input: big
Output:
输入:
1
2
3
# An example with long input, so it selects only one example.
long_string = "big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else"
print(dynamic_prompt.format(adjective=long_string))
输出:
1
2
3
4
5
6
7
8
# 可以看到只给了一个example
Give the antonym of every input
Input: happy
Output: sad
Input: big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else
Output:
Select by maximal marginal relevance (MMR)
这个 selector 的思想是, 选择与当前输入 p 相似的(cosine similarity) example $q_j$ , 但是这个 $q_j$ 还要尽量与 example pool 中 $q_i$ 不要太相似, 这是为了多样性. 原始 paper 中的 next example 选择公式为:
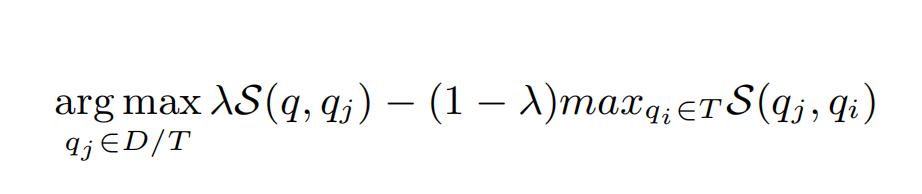
可以看到, 如果下一个 $q_j$ 和 当前的 $p$ 很相似, 但是和其他的 $q_i$ 也非常相似, 那么这个分数也不会太高.
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import (
MaxMarginalRelevanceExampleSelector,
SemanticSimilarityExampleSelector,
)
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
# The list of examples available to select from.
examples,
# The embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# The VectorStore class that is used to store the embeddings and do a similarity search over.
FAISS,
# The number of examples to produce.
k=2,
)
mmr_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
输入:
1
2
# Input is a feeling, so should select the happy/sad example as the first one
print(mmr_prompt.format(adjective="worried"))
输出:
1
2
3
4
5
6
7
8
9
10
Give the antonym of every input
Input: happy
Output: sad
Input: windy
Output: calm
Input: worried
Output:
Select by similarity
这个就很单纯了, 直接使用 cos similarity 来选择最佳的 example, 典型 selector 是 SemanticSimilarityExampleSelector.
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
# The list of examples available to select from.
examples,
# The embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# The VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# The number of examples to produce.
k=1,
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
输入:
1
2
# Input is a feeling, so should select the happy/sad example
print(similar_prompt.format(adjective="worried"))
输出
1
2
3
4
5
6
7
Give the antonym of every input
Input: happy
Output: sad
Input: worried
Output:
Select by n-gram overlap
这个是计算输入的 query 和 example 的 similarity(0-1 之间), 然后根据给定的阈值, 给出满足条件的 example.
阈值为 0.0 表示只排除不相关的 example. 阈值为 -1.0, 表示所有的 example 都会返回. 大于 1.0 表示不返回 example, 默认为 -1.0
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
from langchain_community.example_selector.ngram_overlap import (
NGramOverlapExampleSelector,
)
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# Examples of a fictional translation task.
examples = [
{"input": "See Spot run.", "output": "Ver correr a Spot."},
{"input": "My dog barks.", "output": "Mi perro ladra."},
{"input": "Spot can run.", "output": "Spot puede correr."},
]
example_selector = NGramOverlapExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
example_prompt=example_prompt,
# The threshold, at which selector stops.
# It is set to -1.0 by default.
threshold=-1.0,
# For negative threshold:
# Selector sorts examples by ngram overlap score, and excludes none.
# For threshold greater than 1.0:
# Selector excludes all examples, and returns an empty list.
# For threshold equal to 0.0:
# Selector sorts examples by ngram overlap score,
# and excludes those with no ngram overlap with input.
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the Spanish translation of every input",
suffix="Input: {sentence}\nOutput:",
input_variables=["sentence"],
)
输入:
1
2
3
# An example input with large ngram overlap with "Spot can run."
# and no overlap with "My dog barks."
print(dynamic_prompt.format(sentence="Spot can run fast."))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 可以看到, 即使 "My dog barks." 与输入不相关, 但还是输出了
Give the Spanish translation of every input
Input: Spot can run.
Output: Spot puede correr.
Input: See Spot run.
Output: Ver correr a Spot.
Input: My dog barks.
Output: Mi perro ladra.
Input: Spot can run fast.
Output:
输入:
1
2
3
4
# 不输出 不相关的
example_selector.threshold = 0.0
print(dynamic_prompt.format(sentence="Spot can run fast."))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
Give the Spanish translation of every input
Input: Spot can run.
Output: Spot puede correr.
Input: See Spot run.
Output: Ver correr a Spot.
Input: Spot plays fetch.
Output: Spot juega a buscar.
Input: Spot can run fast.
Output:
1.3 Few-shot prompt templates
上边介绍了一些 example selector , 现在介绍 FewShotPromptTemplate + example selector . 二者实现的功能就是, 首先我们有一堆 example (通常是成对儿的输入和输出) , 然后可以自适应的, 根据不同的输入, 能够自动的 select 合适的 example 与 输入合并, 一同变为 LLM 的 prompt.
也就是说, 不同的输入, 会产生不同的 prompt , 我理解是和 Retrieval-augmented generation (RAG) 类似的效果.
define example:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
""",
},
{
"question": "When was the founder of craigslist born?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who was the founder of craigslist?
Intermediate answer: Craigslist was founded by Craig Newmark.
Follow up: When was Craig Newmark born?
Intermediate answer: Craig Newmark was born on December 6, 1952.
So the final answer is: December 6, 1952
""",
},
{
"question": "Who was the maternal grandfather of George Washington?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
""",
},
{
"question": "Are both the directors of Jaws and Casino Royale from the same country?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: Who is the director of Jaws?
Intermediate Answer: The director of Jaws is Steven Spielberg.
Follow up: Where is Steven Spielberg from?
Intermediate Answer: The United States.
Follow up: Who is the director of Casino Royale?
Intermediate Answer: The director of Casino Royale is Martin Campbell.
Follow up: Where is Martin Campbell from?
Intermediate Answer: New Zealand.
So the final answer is: No
""",
},
]
# format example pool
example_prompt = PromptTemplate(
input_variables=["question", "answer"], template="Question: {question}\n{answer}"
)
define selector:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from langchain_chroma import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_openai import OpenAIEmbeddings
example_selector = SemanticSimilarityExampleSelector.from_examples(
# This is the list of examples available to select from.
examples,
# This is the embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# This is the VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# This is the number of examples to produce.
k=1,
)
FewShotPromptTemplate + example + selector :
1
2
3
4
5
6
7
8
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"],
)
print(prompt.format(input="Who was the father of Mary Ball Washington?"))
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
# 可以看到 prompt 最后只引入了一个 example
Question: Who was the maternal grandfather of George Washington?
Are follow up questions needed here: Yes.
Follow up: Who was the mother of George Washington?
Intermediate answer: The mother of George Washington was Mary Ball Washington.
Follow up: Who was the father of Mary Ball Washington?
Intermediate answer: The father of Mary Ball Washington was Joseph Ball.
So the final answer is: Joseph Ball
Question: Who was the father of Mary Ball Washington?
1.5 Partial prompt templates
这个功能就是类似函数的参数具有默认值.
例子:
1
2
3
4
5
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("{foo} {bar}")
partial_prompt = prompt.partial(foo="666")
print(partial_prompt.format(bar="baz")) # 输出 666 baz
这个也可以使用函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from datetime import datetime
def _get_datetime():
now = datetime.now()
return now.strftime("%m/%d/%Y, %H:%M:%S")
prompt = PromptTemplate(
template="Tell me a {adjective} joke about the day {date}",
input_variables=["adjective", "date"],
)
# date 默认 调用当前时间
partial_prompt = prompt.partial(date=_get_datetime)
# 输出 : Tell me a funny joke about the day 04/25/2024, 23:22:18
print(partial_prompt.format(adjective="funny"))
1.6 PipelinePrompt
PipelinePrompt 能够把多个 prompt 整到一起.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
from langchain_core.prompts.pipeline import PipelinePromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 最终的 prompt
full_template = """{introduction}
{example}
{start}"""
full_prompt = PromptTemplate.from_template(full_template)
# 用于 Introduction
introduction_template = """You are impersonating {person}."""
introduction_prompt = PromptTemplate.from_template(introduction_template)
# example
example_template = """Here's an example of an interaction:
Q: {example_q}
A: {example_a}"""
example_prompt = PromptTemplate.from_template(example_template)
# 用户的输入
start_template = """Now, do this for real!
Q: {input}
A:"""
start_prompt = PromptTemplate.from_template(start_template)
# 将上边的 prompt 合并到一起
input_prompts = [
("introduction", introduction_prompt),
("example", example_prompt),
("start", start_prompt),
]
# 指定谁是谁
pipeline_prompt = PipelinePromptTemplate(
final_prompt=full_prompt, pipeline_prompts=input_prompts
)
print(
pipeline_prompt.format(
person="Elon Musk",
example_q="What's your favorite car?",
example_a="Tesla",
input="What's your favorite social media site?",
)
)
输出 :
1
2
3
4
5
6
7
8
9
10
11
12
13
You are impersonating Elon Musk.
Here's an example of an interaction:
Q: What's your favorite car?
A: Tesla
Now, do this for real!
Q: What's your favorite social media site?
A:
2. Retrieval
Retrieval Augmented Generation (RAG) 可能是目前 LLM 发挥比较大作用的一个应用. 其核心思想是利用外挂的知识库赋予在不同的垂直领域应用能力.
其核心流程如下:
[1] 首先我们要有相应的资源库, source
[2] 然后针对不同的资源, 我们使用相应的 dataloader 将资源数据读取
[3] 由于资源文档比较长, 通常我们要进行分块, 称为 chunk
[4] 将文档 chunk 后, 会对每个 chunk 进行 embedding
[5] embedding 之后, 要进行 store, 这个组件一般称为 vector store
[6] 当我们给定输入的时候, LLM 能够根据语义从 store 中抽取有用的资源,这个过程就是 retrieve
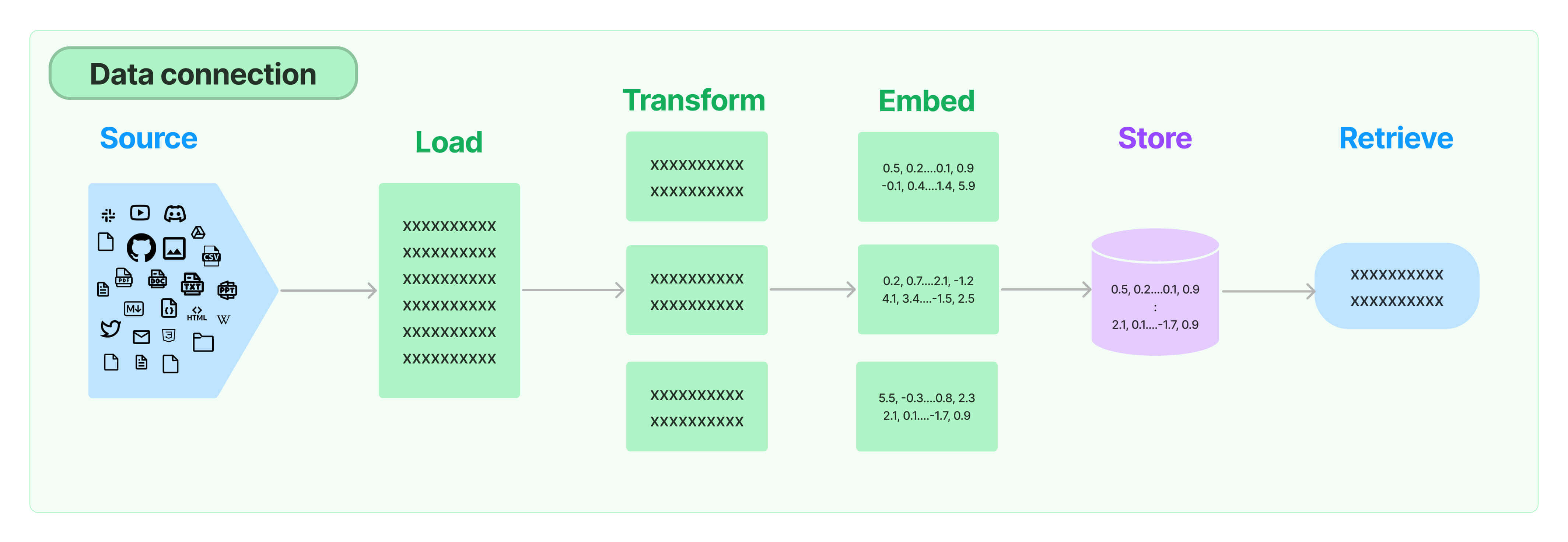
2.1 Dataloader
官方文档集成了很多第三方 dataloader, 甚至可以直接从 arxiv、GitHub 等直接获取数据. 但是常用的可能就是针对 文本 和 csv 的, 而且使用方法类似, 所以这里只学习 文本类型 的.
Document Loader
LangChain 给的例子是继承 BaseLoader, 然后将读到的文本初始化为 Document 对象. 内部有 4 个基本方法: 直接读取所有, 异步读取所有, lazy 读取, 异步 lazy 读取.

例子:
详细代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
from typing import AsyncIterator, Iterator
from langchain_core.document_loaders import BaseLoader
from langchain_core.documents import Document
class CustomDocumentLoader(BaseLoader):
"""An example document loader that reads a file line by line."""
def __init__(self, file_path: str) -> None:
"""Initialize the loader with a file path.
Args:
file_path: The path to the file to load.
"""
self.file_path = file_path
def lazy_load(self) -> Iterator[Document]: # <-- Does not take any arguments
"""A lazy loader that reads a file line by line.
When you're implementing lazy load methods, you should use a generator
to yield documents one by one.
"""
with open(self.file_path, encoding="utf-8") as f:
line_number = 0
for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
# alazy_load is OPTIONAL.
# If you leave out the implementation, a default implementation which delegates to lazy_load will be used!
async def alazy_load(
self,
) -> AsyncIterator[Document]: # <-- Does not take any arguments
"""An async lazy loader that reads a file line by line."""
# Requires aiofiles
# Install with `pip install aiofiles`
# https://github.com/Tinche/aiofiles
import aiofiles
async with aiofiles.open(self.file_path, encoding="utf-8") as f:
line_number = 0
async for line in f:
yield Document(
page_content=line,
metadata={"line_number": line_number, "source": self.file_path},
)
line_number += 1
with open("./meow.txt", "w", encoding="utf-8") as f:
quality_content = "meow meow🐱 \n meow meow🐱 \n meow😻😻"
f.write(quality_content)
loader = CustomDocumentLoader("./meow.txt")
## Test out the lazy load interface
for doc in loader.lazy_load():
print()
print(type(doc))
print(doc)
## Test out the async implementation
async for doc in loader.alazy_load():
print()
print(type(doc))
print(doc)
"""
输出结果一样:
<class 'langchain_core.documents.base.Document'>
page_content='meow meow🐱 \n' metadata={'line_number': 0, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' meow meow🐱 \n' metadata={'line_number': 1, 'source': './meow.txt'}
<class 'langchain_core.documents.base.Document'>
page_content=' meow😻😻' metadata={'line_number': 2, 'source': './meow.txt'}
"""
load() can be helpful in an interactive environment such as a jupyter notebook. Avoid using it for production code since eager loading assumes that all the content can fit into memory, which is not always the case, especially for enterprise data.
2.2 Text Splitters
Once you’ve loaded documents, you’ll often want to transform them to better suit your application. The simplest example is you may want to split a long document into smaller chunks that can fit into your model’s context window.
官方文档给了多种 Splitter, 最常用的为以下 3 种.
Split by character
这个是最简单的 Splitter, 单纯就是使用指定的 character 去切分 text .
例子:
1
2
3
4
5
6
7
8
9
10
11
12
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator=" ", # 指定 separator
chunk_size=5,
chunk_overlap=2,
length_function=len,
is_separator_regex=False,
)
text_splitter.split_text("我是练习时长 达两年半的坤坤")
上述代码中, chunk_size 本意是指进行 split 之后, 后续进行 store 的时候, 最大以多大的 size 作为一个整体进行存储. 但是可以看到这个参数对于 CharacterTextSplitter 不生效, 实际上源码中, 就是简单的用 re.split() 对文档按照 separator 进行切割, 不管子句有多长, 直接返回.
输出:
1
['我是练习时长', '达两年半的坤坤']
因为 LLM 通常对输入有长度限制, 因此 CharacterTextSplitter 不太适合, 可能会超出输入尺寸范围, 而下边的 RecursiveCharacterTextSplitter 可以递归切割子句, 直到每个子句都小于 chunk size.
Recursive Splitter By Character
这个看了源码,它默认的 separator = ["\n\n", "\n", " ", ""], 我的理解是说, 首先会根据\n\n进行切割. 一般来说, 2 个换行分割开的通常是 2 篇文章. 所以会先按照这个尺度进行切割. 如果切割之后, 某篇文章还是太长(大于 chunk size), 那么会继续使用 \n 进行划分切割, 同理直到其长度小于 chunk size.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=5,
chunk_overlap=0,
length_function=len,
is_separator_regex=False,
keep_separator = False
)
text_splitter.split_text(
"我是\n\n练习时长达两年\n半的坤坤"
)
输出:
1
2
3
4
['我是', '练习时长达', '两年', '半的坤坤']
# 可以看到, 首先用`\n\n`进行分割, 因为"我是"的长度小于5, 所以直接存起来,
# 但是后边部分太长, 又基于`\n`进行切割, "半的坤坤"是满足要求的,所以一起存了起来.
# 但是"练习时长达两年"的长度还是大于5, 于是进行了继续的切割. 变为"练习时长达" 和 "两年"
Split by tokens
这个就是使用 NLP 中 token 进行切割, 不同的 tokenizer 有不同的切割方式. 举个例子, 如果一个单词算一个 token, 那就按单词切割. 为什么需要这个呢, 就是有些 LLM 的输入具有 token 数目的限制, 因此最好分割存储的 tokenizer 和 LLM 使用一样的.
这里使用 OpenAI BPE tokenizer : tiktoken, 是BPE 算法的一个实现.
Split by tokens 的使用方法基于上边 2 种 Splitter, 只是切割时调用方法不同:
1
2
3
4
5
6
7
8
9
10
11
12
13
# pip install tiktoken
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding="cl100k_base", chunk_size=100, chunk_overlap=0
) # CharacterTextSplitter 实际不受 chunk_size 的约束
texts = text_splitter.split_text("text")
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name="gpt-4",
chunk_size=100,
chunk_overlap=0,
) # 能够保证子句全部小于chunk_size
texts = text_splitter.split_text("text")
# 此外 encoding参数 和 model_name参数 效果类似, 具体请参考api
Semantic Chunking
这个就是字面意思, 基于 text 之间的语义进行切割, 使得语义相近的尽量在一个 chunk, 但是这个目前(2024 年 4 月 27 日)是个实验性功能. 参考官方文档
由于这个需要计算语义相似度, 所以需要进行 embedding.
例子:
1
2
3
4
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
text_splitter = SemanticChunker(OpenAIEmbeddings())
texts = text_splitter.split_text("text")
这个里边提供了一个 Breakpoints, 用于评估什么时候该切割, 语义相近多少才算相近?
- Percentile
Percentile(百分位数) 是默认的评估标准, 他是计算所有两两句子之间的 difference, 如果大于阈值就给他切开.
例子:
1
2
3
4
text_splitter = SemanticChunker(
OpenAIEmbeddings(), breakpoint_threshold_type="percentile"
# breakpoint_threshold_amount : 默认值
)
阅读源码可以看到,当threshold_type = "percentile" 时, 默认使用 95% 分位数. breakpoint_threshold_amount 参数控制分位数具体大小.
- Standard Deviation
用法类似, 不再赘述. 源码中当threshold_type = "standard_deviation" 时, 默认使用 mean + 3 * std 作为阈值. breakpoint_threshold_amount 参数控制标准差的倍数.
- Interquartile
使用的箱线图方法, 默认使用 mean + 1.5 * iqr, 其中 iqr = q3 - q1, q3 为 75% 分位数, q1 为 25% 分位数. breakpoint_threshold_amount 参数控制q3 - q1的倍数.
2.3 Embedding
官方文档给了很多第三方 embedding 方法. 其实就是训练好的一个 Matrix. 这里使用 openAI 提供的 embedding.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
输出:
1
2
3
4
5
[0.0053587136790156364,
-0.0004999046213924885,
0.038883671164512634,
-0.003001077566295862,
-0.00900818221271038]
Caching
在得到 embedding 之后, 我们可以已经 embedding 过的 token 给他缓存, 如果后续又来了同一个 token, 我们可以直接从 cache 调用, 而不去需要从 embedding matrix 获取.
核心组件为 CacheBackedEmbeddings, 使用例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
underlying_embeddings = OpenAIEmbeddings()
store = LocalFileStore("./cache/") # 表示缓存到本地
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
"""
underlying_embedder: The embedder to use for embedding.
document_embedding_cache: Any ByteStore for caching document embeddings.
batch_size: (optional, defaults to None) The number of documents to embed between store updates.
namespace: (optional, defaults to "") The namespace to use for document cache. This namespace is used to avoid collisions with other caches. For example, you can set it to the name of the embedding model used.
"""
raw_documents = TextLoader("../../state_of_the_union.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
%%time
db = FAISS.from_documents(documents, cached_embedder)
# 输出 CPU times: user 218 ms, sys: 29.7 ms, total: 248 ms
# Wall time: 1.02 s
%%time
db2 = FAISS.from_documents(documents, cached_embedder)
# 输出 CPU times: user 15.7 ms, sys: 2.22 ms, total: 18 ms
# Wall time: 17.2 ms
最后, store 可以换, 比如使用 memory store:
1
2
3
4
5
6
from langchain.embeddings import CacheBackedEmbeddings
from langchain.storage import InMemoryByteStore
store = InMemoryByteStore()
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
2.4 Vector stores
官方文档提供了许多第三方的 Vector stores.
Facebook AI Similarity Search (FAISS) library, 例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = FAISS.from_documents(documents, OpenAIEmbeddings())
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
"""
也可以直接使用 vector 进行 search
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print(docs[0].page_content) # 输出结果是一样的
"""
输出:
1
2
3
4
5
6
7
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
Asynchronous operations
Vector Store 也支持 异步操作, Qdrant is a vector store, which supports all the async operations, thus it will be used in this walkthrough.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# pip install qdrant-client
from langchain_community.vectorstores import Qdrant
db = await Qdrant.afrom_documents(documents, embeddings, "http://localhost:6333")
query = "What did the president say about Ketanji Brown Jackson"
docs = await db.asimilarity_search(query)
print(docs[0].page_content)
"""
# 同理支持 vector 查询
embedding_vector = embeddings.embed_query(query)
docs = await db.asimilarity_search_by_vector(embedding_vector)
"""
"""
# 此外计算 similarity 的时候, 支持 Maximum marginal relevance search (MMR)方法:
query = "What did the president say about Ketanji Brown Jackson"
found_docs = await qdrant.amax_marginal_relevance_search(query, k=2, fetch_k=10)
for i, doc in enumerate(found_docs):
print(f"{i + 1}.", doc.page_content, "\n")
"""
输出:
1
2
3
4
5
6
7
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
2.5 Retrievers
Retrievers 接受用户的 query, 然后从 vector store 中根据规则(不同种类相似度)去搜索得到合适的上下文, 用于后续回答输出.
同样的, 官方文档有多种类型的 Retrievers, 下面简要学习.
Vector store-backed retriever
这个 retriever 是最简单的, 他使用的 search 方法有 similarity search and MMR.
后续其他的高级 retriever 都是基于这个 retriever进行的包装. 都有一个参数 : base_retriever = retriever
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
loader = TextLoader("../../state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever()
# retriever = db.as_retriever(search_type="mmr")
# retriever = db.as_retriever(
# search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5}
# )
# retriever = db.as_retriever(search_kwargs={"k": 1})
docs = retriever.invoke("what did he say about ketanji brown jackson")
MultiQueryRetriever
前边提到的最简单的 retriever, 将用户输入的 query 对于 sotre 中的文本进行相似度计算, 但是有时候输入的 query 可能并不太明确, 导致搜索到的文本不够清晰. 这时可以使用 MultiQueryRetriever, 这个 retriever 内部使用一个 LLM 基于用户输入的 query 进行分析, 输出逻辑性的过渡问题, 这样每个问题都会分别去与 sotre 中的资源计算 similarity. 通过对同一问题生成多个视角,MultiQueryRetriever 或许能够克服基于距离的检索的一些限制,并获得更丰富的结果集。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Build a sample vectorDB
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0) # 指定一个 LLM 基于 query 生成多角度的 query
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
unique_docs = retriever_from_llm.invoke(question)
len(unique_docs)
输出
1
2
3
4
# 可以看到日志默认生成了3个问题(注意这不是最终输出哈~)
['1. How can Task Decomposition be approached?',
'2. What are the different methods for Task Decomposition?',
'3. What are the various approaches to decomposing tasks?']
Contextual Compression Retriever
这个实际上算是一个 wrapper, 本意是用来解决:因为我们不知道用户到低想搜索什么, 所以以会直接放大量的文档给 store 中, 但是这就会导致一个问题, 当我们输入 query 的时候, 有用的信息可能会被淹没在大量的文档中, 这就需要我们对文档信息进行压缩, 把没用的信息过滤掉.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
def pretty_print_docs(docs):
print(
f"\n{'-' * 100}\n".join(
[f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]
)
)
documents = TextLoader("../../state_of_the_union.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
docs = retriever.invoke("What did the president say about Ketanji Brown Jackson")
pretty_print_docs(docs)
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
Document 1:
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
----------------------------------------------------------------------------------------------------
Document 2:
A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.
And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.
We can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling.
We’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers.
We’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster.
We’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.
----------------------------------------------------------------------------------------------------
Document 3:
And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong.
As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential.
While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice.
And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things.
So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together.
First, beat the opioid epidemic.
----------------------------------------------------------------------------------------------------
Document 4:
Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers.
And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up.
That ends on my watch.
Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect.
We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees.
Let’s pass the Paycheck Fairness Act and paid leave.
Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty.
Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
可以看到由于存储的时候, chunk size 比较大, 并且我们要找的信息就仅仅为一句话(淹没在文档中), 所以简单的使用 retriever 会直接将相关的文档全部返回了. 在上边的基础上, 我们对基础的 retriever 进行 warpper :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
# 用于将抽到的 doc 进行 compression, 并从每个文档中仅提取与查询相关的内容。
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
但是这个 compression 会使用 LLM 对抽回的文档进行处理压缩(万一他处理的不好呢?). 官方提供了一种可以不改变原始文档, 但能保留核心信息的 : filters.
例子:
1
2
3
4
5
6
7
8
9
10
11
from langchain.retrievers.document_compressors import LLMChainFilter
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
输出:
1
2
3
4
5
6
7
8
9
Document 1:
Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections.
Tonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service.
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.
不过这个 filter 在过滤的时候, 是把整个文本再吃进去操作, 可能带来更多的 token 计算量. EmbeddingsFilter 可以直接使用 embedding 进行操作.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
最后, 官方提供一个 Pipeline 能够把 splitter, embedding, filter, retriever 整到一起.
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
# EmbeddingsRedundantFilter 内部实现对文本的 embedding 和 去重冗余
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
# filter
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
# 组合
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
# creat retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever # 当然要基于基本的 retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Document 1:
One of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court.
And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson
----------------------------------------------------------------------------------------------------
Document 2:
As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential.
While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year
----------------------------------------------------------------------------------------------------
Document 3:
A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder
----------------------------------------------------------------------------------------------------
Document 4:
Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans.
And if we are to advance liberty and justice, we need to secure the Border and fix the immigration system.
We can do both
3. Tools
Tools 通常和 Agent 搭配使用. 面对复杂的任务, Agent(通常是一个LLM) 通过上下文信息去使用合适的 tool 以完成任务. 一个 tool 通常有以下几个组件:
-
The name of the tool
-
A description of what the tool is
-
JSON schema of what the inputs to the tool are
-
The function to call
-
Whether the result of a tool should be returned directly to the user
The name, description, and JSON schema can be used to prompt the LLM so it knows how to specify what action to take. The function to call is equivalent to taking that action.
Importantly, the name, description, and JSON schema (if used) are all used in the prompt.
Basic Usage Tutorial
这里使用官方的 Wikipedia tool.
1
2
3
4
5
6
7
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
api_wrapper = WikipediaAPIWrapper(top_k_results=1, doc_content_chars_max=100)
tool = WikipediaQueryRun(api_wrapper=api_wrapper)
pritn(tool.name,tool.description,tool.args,tool.return_direct)
tool.run({"query": "langchain"}) # 或者 tool.run("langchain")
输出:
1
'Page: LangChain\nSummary: LangChain is a framework designed to simplify the creation of applications '
Custom Tools
官方提供了一些第三方 tool 可供使用. 不过通常我们会定义自己的 tool.
定义一个 tool 的时候, 需要指定以下信息:
name(required) : 一个 agent 可调用的 tools 的名字需要是 unique 的.
description(recommended) : 告知 agent 这个 tool 的用途是什么.
args_schema(recommended) : Pydantic 类型, 可以用于类型检测, 也可以用于添加一些额外的信息, 最后都会作为 prompt 的一部分.
decorator
1
2
3
4
5
6
7
8
9
10
11
# Import things that are needed generically
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
@tool
def search(query: str) -> str:
"""Look up things online."""
return "LangChain"
print(search.name)
print(search.description)
print(search.args)
输出
1
2
3
4
search
search(query: str) -> str - Look up things online.
{'query': {'title': 'Query', 'type': 'string'}}
1
2
3
4
5
6
7
8
9
10
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
print(multiply.name)
print(multiply.description)
print(multiply.args)
输出:
1
2
3
multiply
multiply(a: int, b: int) -> int - Multiply two numbers.
{'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
可以使用 @tool 的参数指定 tool 的名字, 或者对参数进行描述, 提供额外的信息.
1
2
3
4
5
6
7
8
9
10
11
12
13
class SearchInput(BaseModel):
query: str = Field(description="should be a search query")
@tool("search-tool", args_schema=SearchInput, return_direct=True)
def search(query: str) -> str:
"""Look up things online."""
return "LangChain"
print(search.name)
print(search.description)
print(search.args)
print(search.return_direct)
输出:
1
2
3
4
5
6
search-tool
search-tool(query: str) -> str - Look up things online.
{'query': {'title': 'Query', 'description': 'should be a search query', 'type': 'string'}}
True
Subclassing BaseTool (Recommend)
更加的自定义化, 但是稍微麻烦一些.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
from typing import Optional, Type
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import BaseTool, StructuredTool, tool
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
class SearchInput(BaseModel):
query: str = Field(description="should be a search query")
class CustomSearchTool(BaseTool):
name = "custom_search"
description = "useful for when you need to answer questions about current events"
args_schema: Type[BaseModel] = SearchInput # 指定 schema
def _run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return "LangChain"
async def _arun(
self, query: str, run_manager: Optional[AsyncCallbackManagerForToolRun] = None
) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("custom_search does not support async")
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
class CustomCalculatorTool(BaseTool):
name = "Calculator"
description = "useful for when you need to answer questions about math"
args_schema: Type[BaseModel] = CalculatorInput
return_direct: bool = True
def _run(
self, a: int, b: int, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
"""Use the tool."""
return a * b
async def _arun(
self,
a: int,
b: int,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("Calculator does not support async")
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
search = CustomSearchTool()
print(search.name)
print(search.description)
print(search.args)
'''
custom_search
useful for when you need to answer questions about current events
{'query': {'title': 'Query', 'description': 'should be a search query', 'type': 'string'}}
'''
multiply = CustomCalculatorTool()
print(multiply.name)
print(multiply.description)
print(multiply.args)
print(multiply.return_direct)
'''
Calculator
useful for when you need to answer questions about math
{'a': {'title': 'A', 'description': 'first number', 'type': 'integer'}, 'b': {'title': 'B', 'description': 'second number', 'type': 'integer'}}
True
'''
第三方的 tool 基本都是上述的方法, 这里以 ArXiv tool 为例. 其源代码见: arxiv_tool.py, utilities_tool.py. 核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# 在 arxiv_tool.py 文件中
"""Tool for the Arxiv API."""
from typing import Optional, Type
from langchain_core.callbacks import CallbackManagerForToolRun
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.tools import BaseTool
from langchain_community.utilities.arxiv import ArxivAPIWrapper
class ArxivInput(BaseModel):
"""Input for the Arxiv tool."""
query: str = Field(description="search query to look up") # 用于指定 args_schema
class ArxivQueryRun(BaseTool):
"""Tool that searches the Arxiv API."""
name: str = "arxiv"
description: str = (
"A wrapper around Arxiv.org "
"Useful for when you need to answer questions about Physics, Mathematics, "
"Computer Science, Quantitative Biology, Quantitative Finance, Statistics, "
"Electrical Engineering, and Economics "
"from scientific articles on arxiv.org. "
"Input should be a search query."
)
api_wrapper: ArxivAPIWrapper = Field(default_factory=ArxivAPIWrapper) # 这里做了一个 Wrapper
args_schema: Type[BaseModel] = ArxivInput
def _run(
self,
query: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the Arxiv tool."""
return self.api_wrapper.run(query) # 调用的是 Wrapper 的 run
# ===================================
# 在 utilities_tool.py 中
"""Util that calls Arxiv."""
"""Util that calls Arxiv."""
import logging
import os
import re
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.documents import Document
from langchain_core.pydantic_v1 import BaseModel, root_validator
logger = logging.getLogger(__name__)
class ArxivAPIWrapper(BaseModel):
# 其他函数省略, 就是一些 import 导入检测之类的.
def run(self, query: str) -> str:
try:
if self.is_arxiv_identifier(query):
results = self.arxiv_search(
id_list=query.split(),
max_results=self.top_k_results,
).results()
else:
results = self.arxiv_search( # type: ignore
query[: self.ARXIV_MAX_QUERY_LENGTH], max_results=self.top_k_results
).results()
except self.arxiv_exceptions as ex:
return f"Arxiv exception: {ex}"
docs = [
f"Published: {result.updated.date()}\n"
f"Title: {result.title}\n"
f"Authors: {', '.join(a.name for a in result.authors)}\n"
f"Summary: {result.summary}"
for result in results
]
if docs:
return "\n\n".join(docs)[: self.doc_content_chars_max]
else:
return "No good Arxiv Result was found"
StructuredTool dataclass
StructuredTool 方法将上述 “直接定义方法” 与 “SubClass” 的方法结合起来. 阅读其源代码, StructuredTool 内部也是继承的 Base tool.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class CalculatorInput(BaseModel):
a: int = Field(description="first number")
b: int = Field(description="second number")
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
calculator = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="multiply numbers",
args_schema=CalculatorInput,
return_direct=True,
# coroutine= ... <- you can specify an async method if desired as well
)
print(calculator.name)
print(calculator.description)
print(calculator.args)
输出:
1
2
3
4
5
Calculator
Calculator(a: int, b: int) -> int - multiply numbers
{'a': {'title': 'A', 'description': 'first number', 'type': 'integer'}, 'b': {'title': 'B', 'description': 'second number', 'type': 'integer'}}
Handling Tool Errors
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain_core.tools import ToolException
def search_tool1(s: str):
raise ToolException("The search tool1 is not available.")
search = StructuredTool.from_function(
func=search_tool1,
name="Search_tool1",
description="A bad tool",
)
search.run("test")
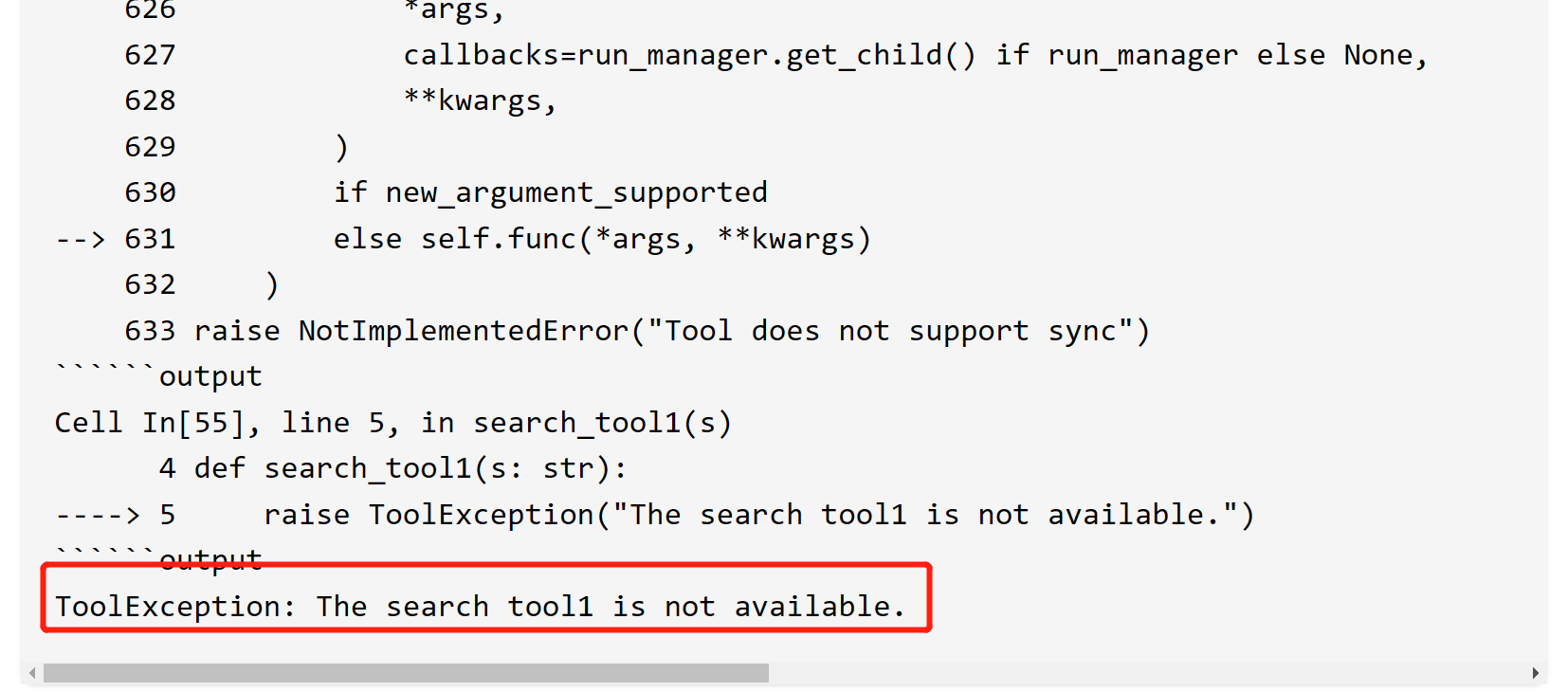
设置 handle_tool_error = True, 可以将 ToolException 的字符串输出:
1
2
3
4
5
6
7
8
search = StructuredTool.from_function(
func=search_tool1,
name="Search_tool1",
description="A bad tool",
handle_tool_error=True,
)
search.run("test") # 输出 'The search tool1 is not available.'
也可以将 handle_tool_error 设置为一个函数, 这个函数必须接受一个 ToolException, 然后给一个字符串输出 str
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def _handle_error(error: ToolException) -> str:
return (
"The following errors occurred during tool execution:"
+ error.args[0]
+ "Please try another tool."
)
search = StructuredTool.from_function(
func=search_tool1,
name="Search_tool1",
description="A bad tool",
handle_tool_error=_handle_error,
)
search.run("test")
# 输出 : 'The following errors occurred during tool execution:The search tool1 is not available.Please try another tool.'